基于微变放大技术的肺结节识别算法研究
时间:2025-09-16 12:26:40 热度:37.1℃ 作者:网络
摘 要
目的 开发一种能够帮助医师定位肺结节的新型识别算法。方法 纳入2023年12月于南京大学医学院附属鼓楼医院胸外科行胸腔镜手术的16例肺结节患者,其中男9例、女7例,平均年龄(54.9±14.9)岁,采集患者60帧/s帧率、1 920×1 080分辨率的胸腔镜肺表面探查数据,并以定间隔保存帧图像,对帧进行分块处理。用以上数据构建一个针对肺部结节识别的算法数据库。结果 在经过优化的多拓扑卷积网络模型中,测试结果显示准确识别率达94.39%。进一步通过整合微变扰乱放大技术的卷积网络模型,在识别肺部结节方面的准确率提高至96.90%。将这2个模型的表现综合评估,整体的识别准确率达95.59%。据此,我们推断所提出的网络模型适用于肺部结节的识别任务,且融合微变放大技术的卷积网络在准确率上表现更为优异。结论 我们提出的技术模型能够显著提高肺部结节识别的精度和定位准确度并帮助术者在胸腔镜手术过程中定位肺结节。
正 文
肺癌是一个全球性的公共卫生问题,全球每年有250万新发病例和180万死亡病例[1]。肺癌是发病率最高的癌症,也是全球癌症死亡的主要原因[1]。随着医学影像技术的进步、高分辨率多层CT技术的普及,医生能够更早地发现肺小结节,从而进行早期干预。针对肺小结节,传统的检查手段如胸部CT、穿刺活检、支气管镜、正电子发射计算机断层显像(PET-CT)等难以明确诊断。而随着腔镜技术与微创技术的发展,电视胸腔镜手术已经成为肺小结节诊疗的金标准而被广泛开展[2]。因此,如何在术前尽快对肺小结节精确定位,以最大限度地精准切除肿瘤、保护肺功能,是胸外科医生面临的重要课题。
随着计算机视觉技术的发展,越来越多的肺部结节图像识别研究开始被开发[3]。传统方法中Murphy等[4]提出了一种实性肺结节的可疑位置推荐算法。该算法首先计算肺部CT图像各体素的形状指数和曲率,对2个指标阈值化处理来寻找可能存在实性肺结节的种子点,最后根据这些种子点来分割肺结节以推荐可疑位置。Jacobs等[5]实现了一个半实性肺结节的可疑位置推荐算法,直接通过区间阈值对CT 图像进行阈值化,并对阈值化后图像进行形态学操作求取连通区域,从而推荐可疑肺结节的位置。由于有些贴在胸膜上的大型肺结节与胸膜组织的区分度较小,Setio等[6]提出了专门针对大型肺结节的可疑位置推荐算法,使用了多级形态学方法提取大结节。
传统的机器学习的肺部结节识别方法,如径向基函数的支持向量机(support vector machine,SVM)方法,需要大量的手动特征提取工作,且计算量大、效率低,存在一定的局限性[7]。而深度学习技术可以自动学习有用的特征,从而减少手动特征提取的工作量,提高识别准确率[8]。
Chen等[9]提出了一种基于语义分割(semantic segmentation,SegNet)的胸部CT肺癌辅助诊断模型,SegNet的新颖之处在于解码器对其低分辨率输入特征图进行采样,并使用相应编码器通过最大池化索引执行上采样,这大大减少了样本特征学习的需要。
视觉几何组(visual geometry group,VGG)模型是由牛津大学科学工程系VGG提出的一种在图像识别领域使用的深度卷积神经网络(deep convolutional neural network,DCNN)模型,具有精炼和高效的特点。VGG模型精炼且高效是因其使用了一系列3×3的小型卷积层,并通过堆叠多个这样的卷积层来增加感受野,而不是使用较大的卷积核。Chowdary等[10]将VGG模型与机器学习算法结合应用于肺炎诊断领域,VGG模型与机器学习算法的结合使得算法的准确性大大提升。
目标检测算法YOLO(You Only Look Once)是一种是基于深度神经网络的目标检测算法,是近几年常用在影像中实时识别和定位多个对象的深度学习检测算法之一,也被广泛应用于医学识别领域。但YOLO存在识别精度不够高、检测速度慢等问题。因此,本文改进了YOLO中的CBS模块,参考VGG模型,添加了一种小型的3×3卷积层与颈部层(Neck层)组成的卷积网络结构,构建了一种新的多拓扑卷积网络模型。结合微变放大技术放大结节波动,利用改进的多拓扑卷积网络模型提取肺部结节图像的特征,形成一种新的肺部浅层结节检测模型,以提高肺部结节检测精度。
本文构建了一个通过观察肺表面识别肺部结节的算法数据库,该数据库包含13 552张图片和对应的标注。胸外科医师可以在该数据库基础上,展开识别算法研究;改进了多拓扑卷积网络模型,并结合微变放大技术,构建了肺部结节的识别算法框架。
1 资料与方法
1.1 临床资料
纳入2023年12月于南京大学医学院附属鼓楼医院胸外科行胸腔镜手术的16例肺结节患者,其中男9例、女7例,年龄(54.9±14.9)岁,身高(1.65±0.09)m,体重(67.5±11.8)kg,体重指数(24.6±3.3)kg/m2;见表1。患者均在术前行胸部CT检查,且均能够在CT影像上被诊断为距离肺表面1 cm以内的肺结节。该诊断由3名具有5年以上工作经验的胸外科中级或高级职称医师及1名具有5年以上工作经验的医学影像科医师共同完成。

16例患者的肺表面结节均在术后的病理检测中证实其肺表面观察到并行胸腔镜手术切除的肺结节组织学类型为原位癌或微浸润腺癌。
1.2 DLR数据库的建立
在16例患者的胸腔镜检查过程中,以60帧/s的帧率,采集1 920×1 080分辨率的患者胸腔镜探查肺表面视频,并以定间隔保存帧图像,对帧进行分块处理,以备实验用。
经过上述处理,本文构建了1个针对肺部结节识别的算法数据库,命名为The Dataset of Lung nodule Recognition(DLR),该数据库包含13 552张图片和对应的标注,平均每例入组患者拥有847张图片与标注。部分数据库节选图见图1。
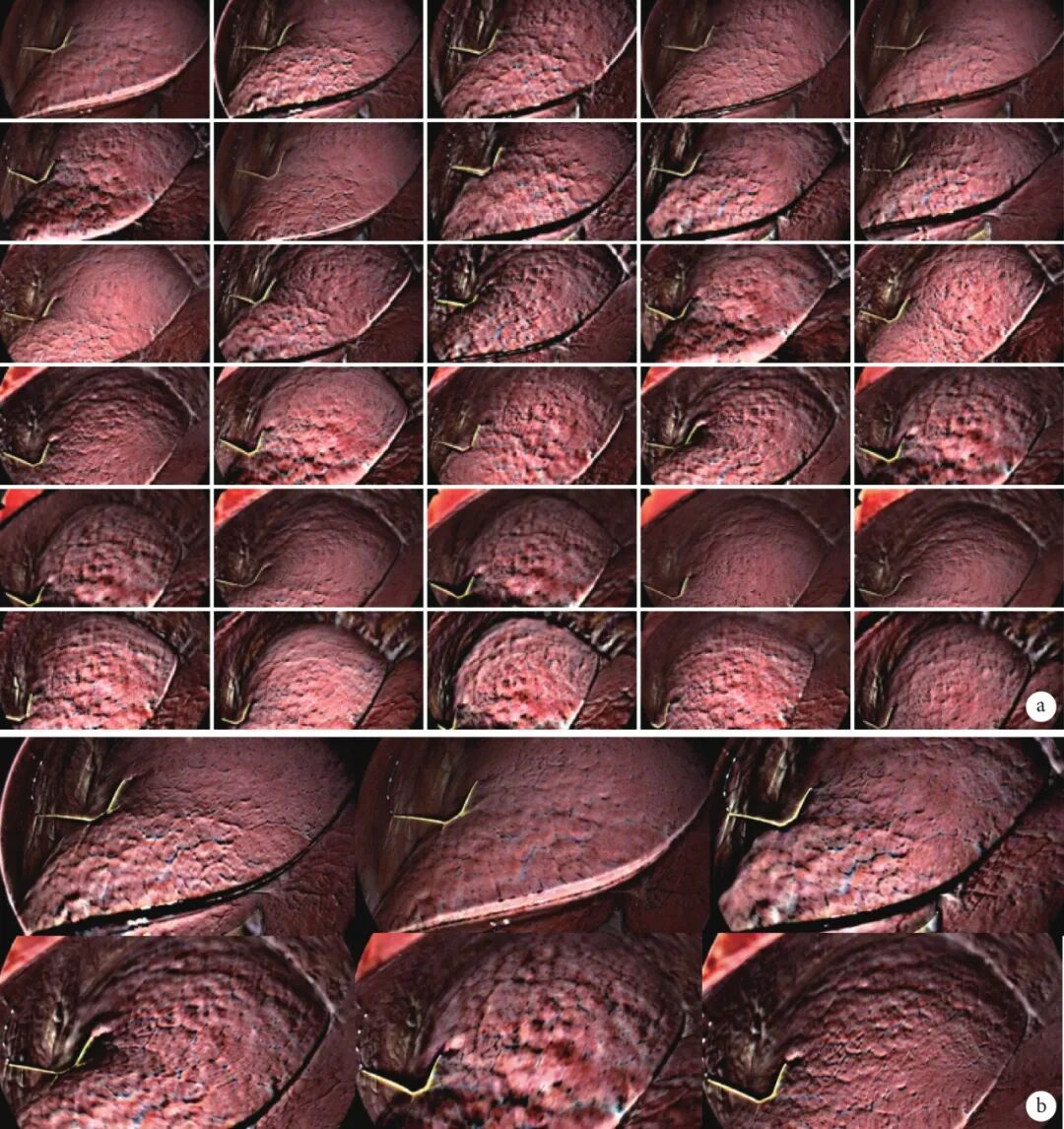
图1 DLR数据库中的部分图像
a:30张节选图;b:6张节选图
1.3 基于微变放大的肺部结节识别算法
1.3.1 基于改进的多拓扑卷积网络的结节定位
改进的多拓扑卷积网络分为3个部分,分别是骨干网络(Backbone)、中间网络(Neck)和特征预测网络(Prediction)。其中骨干网络由DarkNet53网络组成,在该网络中包含全连接层在内的53层卷积层,且在每个下采样过程中融入残差结构,增强对底层特征信息的敏感度。每个卷积层则包含卷积运算层、批归一化层(batch normalization,BN层)和激活函数层,本模型中使用的函数是修正线性单元(rectified linear unit,ReLU)的变体Leakey ReLU。在卷积层中添加BN层可以达到加快网络训练收敛速度、防止梯度消失和过拟合的目的。在中间网络中则使用路径聚合网络(path aggregation network,PANet),这是一种金字塔式的特征提取网络,但其采用的是自下而上的特征传播方式,即从底到顶的信息融合,进一步增加了网络对各层信息的敏感度,提高网络训练效率。同时PANet网络模型中加入了空间金字塔池化模块(spatial pyramid pooling,SPP),极大地提高了感受野,提高网络训练效率与精度。
本实验从SegNet网络中汲取灵感,在YOLO的基础上添加了一种名为空洞卷积(atrous convolution)的注意力机制(attention mechanism),其作用是在卷积层结构中插入了孔加宽技术,算法流程见附件表1。
这种技术可以让卷积的作用范围更大,模型可以更准确地捕捉到一些细节。这种改进的使用大的卷积核大小(kernel size)来捕获全局特征的多拓扑卷积网络的注意力机制能够带来优秀且密集的上下文信息,同时与循环扩展金字塔模块(recurrent expanded pyramid,REP)结合,为不同的注意力映射提供了更多的梯度多样性。此外,还允许深度卷积网络中的梯度流和反向传播过程得到更好的优化,以改善模型的表现;见附件图1。
将分块帧图像集分为训练集和测试集,对训练集进行标注,存在结节的位置标注为Pulmonary Nodule,导入改进的多拓扑卷积网络模型。
1.3.2 融合微变放大的结节定位
将采集输入的视频看成一组视频帧组成的序列,应用空间分解对帧图像进行时间分割,放大变化运动的信号,以此揭示隐藏的信息。
对输入的视频帧进行空间分解,即在每一帧上建立高斯或者拉普拉斯金字塔,按照不同空间频率与信噪比建立不同级别金字塔,以便提高空间高频适用性。时间分割,即所谓的时域滤波,放大某一固定像素点频段而保持其他频段不变。对于每一级别的放大后叠加到滤波前的部分,最后对放大后的金字塔进行重建,算法流程见附件表2。
经过放大后的视频按定间隔取帧,同样保存帧图像并对帧进行分块处理,将分块帧图像集分为训练集和测试集,对训练集进行标注,存在结节的位置标注为Pulmonary Nodule,导入上一节所述的改进的多拓扑卷积网络。
1.4 统计学分析
采用软件SPSS 26.0进行统计学分析。正态分布的计量资料以均数±标准差(x±s)描述;计数资料以频数和百分比(%)描述。
1.5 伦理审查
本研究通过南京大学医学院附属鼓楼医院伦理委员会批准,编号:2023-582-01。
2 结果
从原始数据中选取部分图片输入到微变放大网络之中,通过微变放大,可以很明显看出一些细小的变化;见图2。
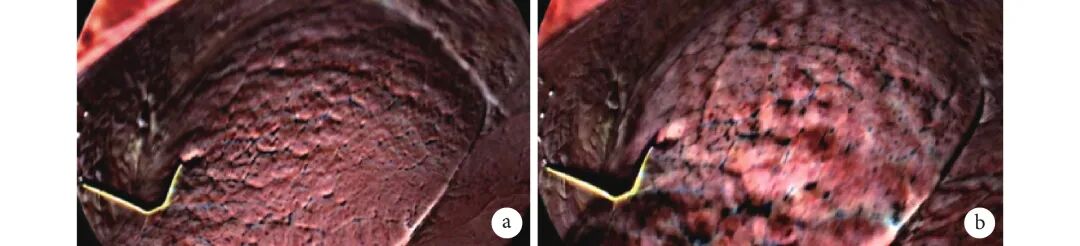
图2 微变放大前后对比图
a:放大前;b:放大后
随后把数据库中另一份数据集图片输入到改进的多拓扑卷积网络之中,进行训练,训练出相应模型。此外,我们对微变放大网络处理过的图片输入到多拓扑卷积网络之中,对这个网络进行二次训练。训练出融合微变放大的网络模型。
此时,可以得到2个训练好的网络模型。分别选取测试图片对2个网络模型进行测试。选取独立于训练集的100多张图片进行测试。改进的多拓扑卷积网络与融合微变放大网络2个模型对肺部结节定位测试结果见图3~4。

图3 改进的多拓扑卷积网络的结节定位测试结果

图4 融合微变放大网络的结节定位测试结果
其中图片上识别框标记的位置表示网络模型识别的结节区。通过图3与图4的对比,可以看出融合了微变放大的网络模型中识别框有部分重叠区域,其识别准确率更高。
通过对所有受测试图片的准确率统计,我们也可以验证上面的结论。在改进的多拓扑卷积网络中测试准确识别率为94.39%,而经过融合微变扰乱放大的卷积网络中,对肺部结节的识别率达96.90%;见表2。综合2个模型来看,识别准确率达到95.59%,因此我们提出相应网络可以用在肺部结节识别上,并且融合的微变放大卷积网络识别准确率更高。
利用本文提出的模型体系检测识别出肺部结节区域,辅助术者进行手术,切除肺部组织内部存在结节,验证了检测识别的准确性;见图5。
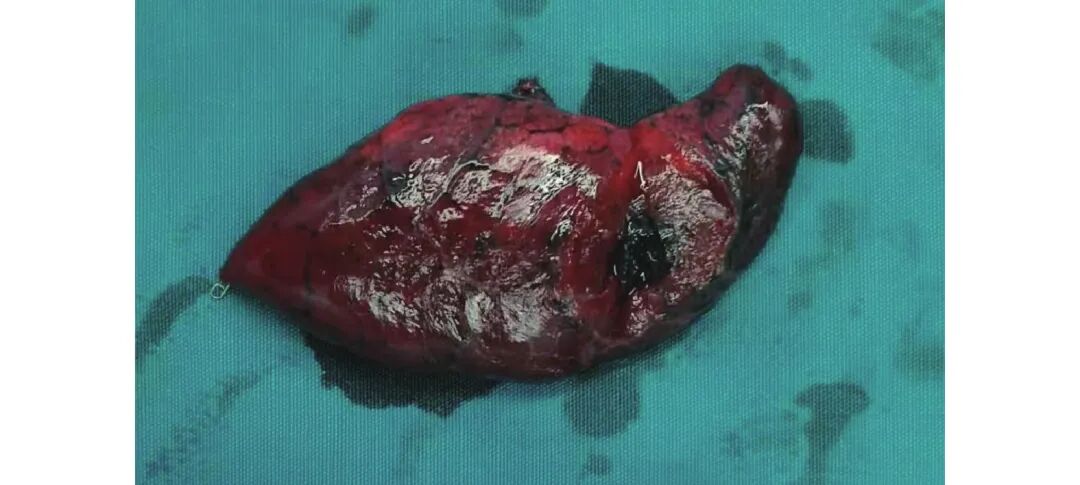
图 5 术中识别成功后切割的肺部结节块
3 讨论
肺结节在影像学上的表现与病理结果密切相关,大多为原位癌、微浸润癌,少部分为肿瘤样病变、良性肿瘤。肺结节病灶演变缓慢,但其转移风险较高。因此,胸腔镜下切除肺结节成为临床治疗的主要手段。然而,由于早期肺结节尺寸小、位置深、密度低,其术前定位成为手术成功的关键因素。术中仅依靠术者的观察和传统的触诊很难精确定位病灶部位,这致使转行肺叶切除甚至中转开胸的比例较高,增加了手术创伤[11]。文献[12]报道,由于传统定位失败,胸腔镜下肺部结节切除手术中转开胸的比例高达46%。目前,肺结节胸腔镜术前定位的方法主要包括 CT 引导定位、电磁导航支气管镜引导定位、近红外荧光成像定位、超声支气管镜引导定位和计算机辅助导航系统。相对于肺结节病灶术前定位的常规方法,本文利用改进的多拓扑卷积网络结构和多尺度检测方法,有效提高了结节的检测精度和定位准确度。同时对采集的视频进行微变放大,放大细节上的变化,进而可以辅助术者进行手术。同时其避免了术前定位带来的有创操作及可能的并发症风险,能够帮助术者在胸腔镜手术过程中定位肺结节。
本文结果显示,通过微变放大后的图像,经过改进的多拓扑卷积网络的处理,标注出患者肺部的结节,比较直观便捷,与本文理论中所阐述的一致。使用训练后的模型,对测试组进行测试,综合准确率达到95.59%。此外,对于独立的对照图像集,本文提出的系统识别准确率也较高。本文提出的算法在实际临床手术中,通过辅助术者手术,其准确性也得到了验证。
尽管本研究中的两种模型在辅助肺结节的诊断中取得了一定的成果,但在临床实践的应用中仍面临许多挑战。主要挑战可以归纳为以下3个方面。首先,最大的挑战是数据的可用性。计算机算法是一门数学科学,而可靠的算法模型需要大量高质量的训练数据。然而,由于患者隐私保护及规范严格的伦理审查,许多医院或研究机构难以实现大量研究数据的收集。
其次,模型的鲁棒性和泛化性会影响识别结果。鲁棒性是指模型的抗干扰能力,即面对异常数据,模型的性能稳定能力。泛化性是指模型计算非训练数据的准确性,即从不同医院来源的肺表面数据中获得准确结果的能力。模型的鲁棒性和泛化性在本研究中会受到不同的拍照设备、光照条件、个体差异的影响。
最后,相较于传统的肺结节定位技术,尽管本研究中提出的算法模型可以实现无创定位肺表面结节,但对于位置较深的肺部结节,由于其在肺部表面几乎不存在表征,本文提出的算法系统仍较难实现识别定位。而传统的肺结节定位技术则并不受结节位置的影响。
肺结节的胸腔镜手术需准确定位肺结节。术前定位是胸外科医师不可绕过的一大问题,但由于肺小结节的体积较小,形态、位置复杂,术前定位方式的选择、并发症的可能亦是胸外科医师不可忽视的重要部分。本文从计算机视觉角度出发,利用改进的多拓扑卷积网络并以放大技术对结节定位。对多拓扑卷积网络进行改进,在卷积层中添加BN层,加快了网络训练收敛速度、防止了梯度消失和过拟合;在中间网络中则使用PAN技术,增加了网络对各层信息的敏感度,提高网络训练效率;同时加入了SPP模块,极大地提高了感受野,提高了网络训练效率与精度;此外使用大 kernel size来捕获全局特征,带来优秀且密集的上下文信息,以结合与更丰富的场景理解,同时与REP模块结合加快推力场景的推力速度同时,经过微变放大处理后的视频图像,定位准确性好,误差较小。
同时不能忽视的是,本文构建的系统无法识别位置较深的肺部结节,对于较深结节表征在肺部表面的特征尚在研究之中,与传统肺结节定位技术结合也是下一步的研究方向和任务。
此外,本文构建了一个针对肺部结节识别的算法数据库(DLR),包含13 552张图片和对应的标注,为后来研究者提供数据支持,同时会不断更新与维护该数据库。
利益冲突:无。
作者贡献:张子睿、王涛设计并监督研究;张子睿、史校铭参与临床信息收集以及数据库的建立;张子睿、焦子宸进行算法设计及数据分析,直接参与验证可行性;张子睿撰写文章;王涛参与研究管理。所有作者都可以访问本研究中的所有数据,参与讨论,并同意出版。
本文附件图表见本刊网站电子版。

