睿宾Agent与主流大语言模型医学文献解读能力比较:以食管癌为例
时间:2025-09-02 12:11:56 热度:37.1℃ 作者:网络
摘 要
目的 探讨人工智能在医学科研辅助中的应用价值,分析实现模型指令精准执行、模型解读完整性提升及控制幻觉的关键路径。方法 以食管癌研究为场景,选取论著、病例报道、综述、社论、指南5类文献进行模型解读测试。从识别准确率、格式正确率、指令执行精确度、解读可靠性、解读完整性5个维度系统评估模型性能,比较睿宾Agent与GPT-4o、Claude 3.7 Sonnet、DeepSeek V3和豆包-pro模型在医学文献解读任务中的表现差异。结果 共纳入15篇文献,每种类型各3篇,5个模型共完成1 875次测试。睿宾Agent因社论类型识别准确率差,导致总体识别准确率显著低于其他模型(92.0% vs. 100.0%,P<0.001);在格式正确率方面,睿宾Agent显著优于Claude 3.7 Sonnet(98.7% vs. 92.0%,P=0.002)和GPT-4o(98.7% vs. 78.9%,P<0.001);在指令执行精确度方面,睿宾Agent优于GPT-4o(97.3% vs. 80.0%,P<0.001);在解读可靠性方面,睿宾Agent显著低于Claude 3.7 Sonnet(84.0% vs. 92.0%,P=0.010)和DeepSeek V3(84.0% vs. 94.7%,P<0.001)。在解读完整性方面,睿宾Agent、GPT-4o、Claude 3.7 Sonnet、DeepSeek V3和豆包-pro的中位评分分别为0.71、0.60、0.85、0.74和0.77。结论 睿宾Agent在医学文献格式化解读与指令执行精确度方面优势显著,未来需重点优化社论类型识别能力、加强各类文献核心要素覆盖能力以提升解读完整性,并通过优化置信机制提升内容可靠性,保障医学文献解读的严谨性。
正 文
随着医学研究文献数量的持续快速增长,人工智能(artificial intelligence,AI)辅助科研成为医务工作者了解实时研究热点以及提高科研效率的必然选择。尽管大型语言模型(large language models,LLMs)在智能问答、辅助诊断、导诊分诊等医疗领域展现出较好的应用前景[1-3],但其对长文本医学文献的系统化解读能力仍存在研究空白,尤其缺乏针对多类型文献解读的可靠性验证。当前通用LLMs存在指令执行偏差、解读内容完整性不足及幻觉生成三大瓶颈,严重影响AI辅助科研的严谨性[4-6]。睿宾Agent是基于当下通用LLMs,通过自然语言处理及医学适配算法搭建的医学科研专用模型,致力于实现医学英文文献的精准化信息提取。本文以食管癌研究为范式场景,系统对比睿宾Agent与主流通用LLMs(GPT-4o、Claude 3.7 Sonnet、DeepSeek V3及豆包-pro)在论著、病例报道、综述、社论和指南共识5类文献中的解读能力差异。通过设计多维解读评估体系,重点探究提升模型指令执行精准度的路径,优化复杂文献解读完整性策略以及控制医学信息幻觉生成的关键机制,旨在为医学专用LLMs的性能优化提供可行措施,推动AI辅助科研在真实医学研究场景中的可靠应用。
1 资料与方法
1.1 测试数据集及测试方法
非英语母语研究者(尤其是基层研究者)英文文献阅读效率低,亟需LLMs辅助科研阅读,本研究通过系统化检索策略,从PubMed数据库筛选食管癌相关英文文献构建测试数据集。文献检索时间为2025年4月23日。文献纳入标准:① 发表于近10年的英文文献;② 来源于高影响力期刊(收录于Scientific Citation Index数据库);③ 文献类型为论著、病例报道、综述、社论和指南;④ 文献文档中包含完整的文章信息(题目、作者、期刊名、发表年份和DOI);⑤ 文献内容符合EQUATOR网站报告指南标准;⑥ 文献书写格式与提示词预设格式相符,如论著符合“背景与目的、方法、结果、结论、讨论、局限性、未来展望”,指南符合“文章信息、摘要、主要建议/问题和建议、各小标题内容总结、结论与展望”等,供大模型根据提示词要求进行信息提取。检索采用主题词“esophageal neoplasms”并扩展自由词(包括“esophageal neoplasm”“esophageal cancer”“cancer of the esophagus”等)。所有文献经两名独立研究人员复核确认其内容完整性、类型代表性及报告规范性,适用于模型解读任务。数据处理方法:将符合要求的文献纳入测试数据集后除更改文档名外(避免文档名提供额外信息),不作特殊预处理。即保留参考文献、目标文献外的其他文献信息等,目的是模拟研究者使用LLMs解读文献的常规操作,同时为后续评价模型指令执行情况提供依据。
研究纳入测试的LLMs包括:睿宾Agent、GPT-4o、Claude 3.7 Sonnet、DeepSeek V3和豆包-pro(以下分别简写为睿宾、GPT、Claude、DeepSeek、豆包),更新日期为2025年4月24日。睿宾是由四川大学华西医院消化内科胡兵团队联合华为技术有限公司、上海惠灏一生信息科技有限公司、成都智算中心共同研发的一款医学科研专用模型。该模型基于“华西黉医”医学大模型及DeepSeek等通用LLMs架构,深度融合自然语言处理技术与医学领域知识适配算法构建而成[7]。其核心设计目标是为医学科研工作者提供操作简便的一站式科研辅助平台,实现对医学英文文献的高精度信息提取与结构化解析。国内模型通过官网进行解读测试,国外模型则通过调用接口进行测试。研究人员根据调试确定最优的通用提示词,用于引导各模型完成文献格式化解读任务。通用提示词内容包括:角色设定为医学文献解读专家,技能包括文献精准分类及文献格式化解读,注意解读内容尽量详细,解读基于原文不可胡编乱造,删除资金支持、参考文献等类似内容。模型使用调试后的提示词对每篇文献进行解读,每篇文献重复解读5次。
1.2 解读评价体系
各模型输出的解读结果由5位获得博士学位且经过科研培训的胃肠病学研究人员进行独立评价。5位研究人员在开始评价前均接受大约1 h的文献解读效果评价培训。评价体系涵盖5个核心指标[8],各指标定义及计算公式如下:
识别准确率(recognition accuracy,RA):评价模型是否正确识别文献类型。RA=正确识别研究类型的次数/总解读次数×100%。
格式正确率(format accuracy,FA):评价模型是否按照预设提示词要求的格式进行解读。FA=按照提示词要求格式正确解读文献的次数/总解读次数×100%。
指令执行精确度(instruction execution accuracy,IEA):评价模型是否精确执行了提示词中的关键指令(主要是排除冗余信息、聚焦核心内容的指令)。IEA=完全按照提示词排除冗余信息并提取核心内容的次数/总解读次数×100%。
解读可靠性(content reliability rate,CRR):评价模型解读内容是否存在编撰或与原文不符的信息(即幻觉信息)。CRR=解读内容中无编撰信息的次数/总解读次数×100%。
解读完整性(content completeness index,CCI):评价模型解读内容覆盖原文关键信息的全面程度。由医学文献解读领域专家为每种类型的每篇文献预先制定详细、标准化的内容评分量表。量表针对各类型文献必须包含的核心要素(如研究背景、方法、结果、结论、局限性等)分配具体分值。CCI=解读结果中涵盖要素的实际得分/该篇文献评分量表的总分。
1.3 统计学分析
所有统计分析均使用R 4.5.1软件。计数资料以频数和百分比表示,组间比较采用χ2检验或Fisher确切概率法,最后采用Fleiss’s Kappa检验进行一致性分析。计量资料首先采用Shapiro-Wilk检验进行正态性检验。呈正态分布的计量资料以均数±标准差(x±s)描述,组间比较采用单因素方差分析。呈偏态分布的计量资料以中位数(上下四分位数)描述,组间比较采用Kruskal-Wallis检验。若Kruskal-Wallis检验结果具有统计学意义,则进一步行Dunn事后两两比较。进行多重比较时采用Bonferroni校正P值。采用组内相关系数(intra-class correlation coefficient,ICC)对计量资料进行一致性分析。双侧检验水准α=0.05。
2 结果
2.1 标准化内容评分量表的可靠性
最终纳入15篇文献[9-23],涵盖论著、病例报道、综述、社论和指南五种类型,每类各3篇。各模型于2025年4月24—25日完成测试集解读。CCI经Shapiro-Wilk正态性检验,统计量W=0.966(P<0.001),不符合正态分布,故后续分析采用非参数检验方法。计数资料评价者间一致性检验采用Fleiss’s Kappa检验,结果显示所有模型Kappa值均>0.80,表明5位评价者间的判断具有高度一致性,这与评价前的标准化培训直接相关。计量资料评价者间一致性检验采用ICC评估。GPT、DeepSeek、豆包和睿宾的ICC值均>0.95,提示评分者对上述模型CCI的评判一致性极佳。Claude的ICC值为0.826,表明一致性良好。上述结果反向验证了本研究采用的标准化内容评分量表在评估CCI时具有可靠的适用性与可重复性,为后续模型性能分析提供了方法学保障。
2.2 总体解读结果
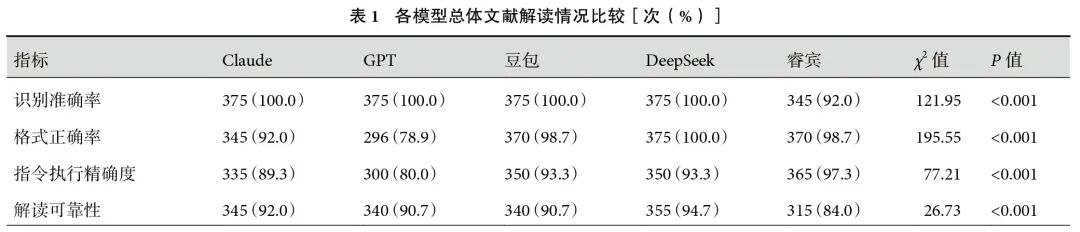
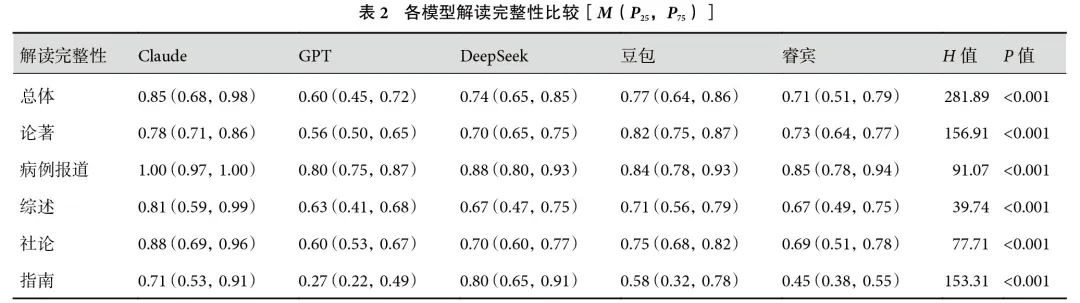
5个模型共完成1 875次测试,各模型总体解读结果见表1。RA方面,睿宾低于其他模型(92.0% vs. 100.0%,P<0.001)。FA方面,DeepSeek(100.0%)、睿宾(98.7%)和豆包(98.7%)模型间无显著差异,但均显著高于Claude(92.0%)和GPT(78.9%)。其中,DeepSeek优于Claude(P<0.001),睿宾和豆包优于Claude(P<0.001),3个模型均优于GPT(P<0.001)。IEA方面,GPT(80.0%)显著低于其他模型,其中睿宾表现最佳(97.3%)。CRR方面,睿宾(84.0%)显著低于Claude(92.0%,P=0.010)和DeepSeek(94.7%,P<0.001),但与GPT(90.7%)和豆包(90.7%)无显著差异。睿宾、GPT、Claude、DeepSeek、豆包的总体CCI中位数分别为0.71、0.60、0.85、0.74和0.77,其中Claude总体CCI最高,其次是DeepSeek和豆包。睿宾的总体CCI高于GPT但低于DeepSeek和豆包;见表2。
2.3 各类型文献解读结果
2.3.1 论著
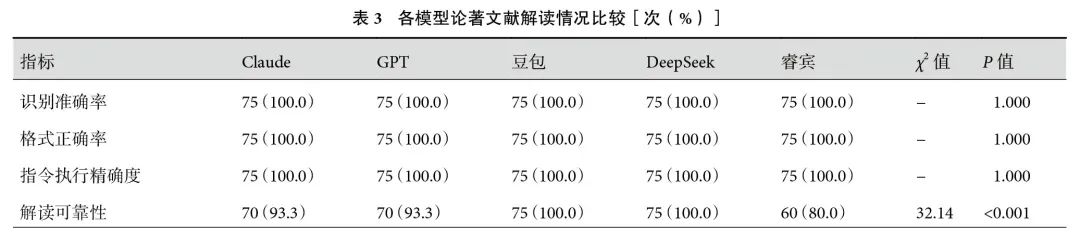
5个模型的RA、FA和IEA无显著差异。CRR方面,Claude、GPT、DeepSeek和豆包差异无统计学意义,其中DeepSeek和豆包的CRR显著高于睿宾(100.0% vs. 80.0%,P=0.001);见表3。在CCI方面,Claude和豆包CCI较高,分别为0.78(0.71,0.86)和0.82(0.75,0.87),其次是DeepSeek和睿宾,分别为0.70(0.65,0.75)和0.73(0.64,0.77),GPT的CCI最低;见表2。
2.3.2 病例报道
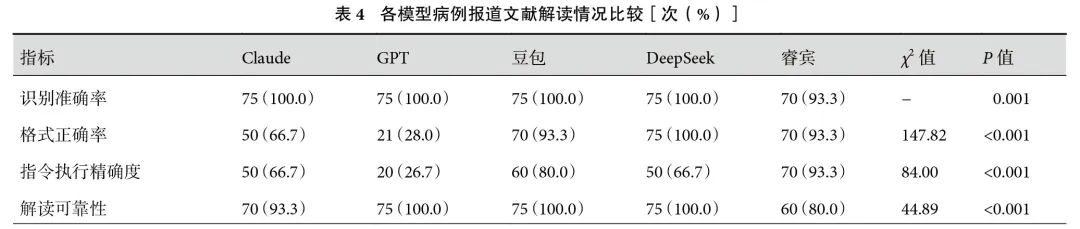
RA方面,5个模型两两比较差异无统计学意义(P>0.05)。DeepSeek、豆包和睿宾的FA分别为100.0%、93.3%和93.3%,差异无统计学意义(P>0.05),三者均优于Claude(66.7%,P<0.001)和GPT(28.0%,P<0.001)。IEA方面,睿宾和豆包差异无统计学意义(93.3% vs. 80.0%,P=0.123),其中睿宾优于Claude(66.7%)、GPT(26.7%)和DeepSeek(66.7%)。Claude和睿宾的CRR无显著差异(93.3% vs. 80.0%,P=0.123)。而GPT、DeepSeek和豆包的CRR均为100.0%,显著高于睿宾,差异均有统计学意义(P<0.001);见表4。病例报道解读CCI最高的模型是Claude[1.00(0.97,1.00)],最低的模型是GPT[0.80(0.75,0.87)]。DeepSeek和睿宾的CCI分别为0.88(0.80,0.93)和0.85(0.78,0.94),差异无统计学意义(P=1.000)。各模型病例报道解读结果见表2。
2.3.3 综述
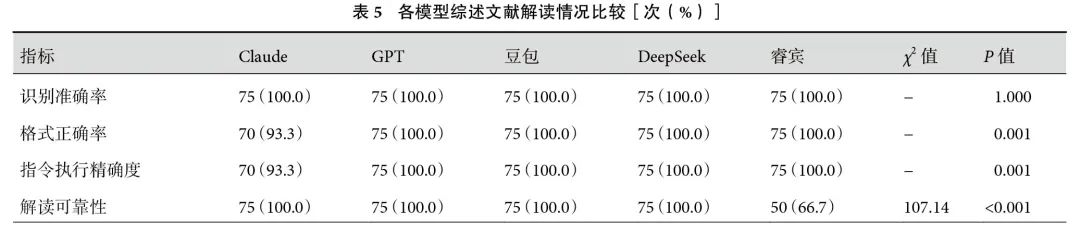
RA、FA和IEA方面,5个模型两两比较差异无统计学意义(P>0.05)。睿宾解读综述时的CRR显著低于其他模型(66.7% vs. 100.0%,P<0.001);见表5。Claude的CCI为0.81(0.59,0.99),显著高于DeepSeek[0.67(0.47,0.75),P=0.002]和睿宾[0.67(0.49,0.75),P=0.002]。DeepSeek和睿宾的CCI差异无统计学意义(P=1.000);见表2。
2.3.4 社论
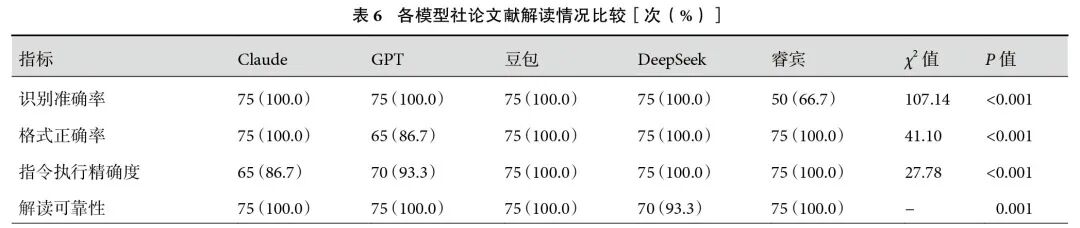
睿宾的RA显著低于其他模型(66.7% vs. 100.0%,P<0.001)。同时,GPT的FA显著低于其他模型(86.7% vs. 100.0%,P=0.013)。DeepSeek、豆包和睿宾的IEA显著高于Claude(100.0% vs. 86.7%,P=0.023)。解读社论时,CRR方面,5个模型两两比较差异无统计学意义(P>0.05);见表6。在CCI方面,Claude和豆包差异无统计学意义[0.88(0.69,0.96)vs. 0.75(0.68,0.82),P=0.501],二者均优于GPT[0.60(0.53,0.67),P均<0.001]和睿宾[0.69(0.51,0.78)](Claude vs.睿宾:P<0.001,豆包vs.睿宾:P=0.008)。此外,Claude的CCI高于DeepSeek[0.88(0.69,0.96)vs. 0.70(0.60,0.77),P<0.001];见表2。
2.3.5 指南
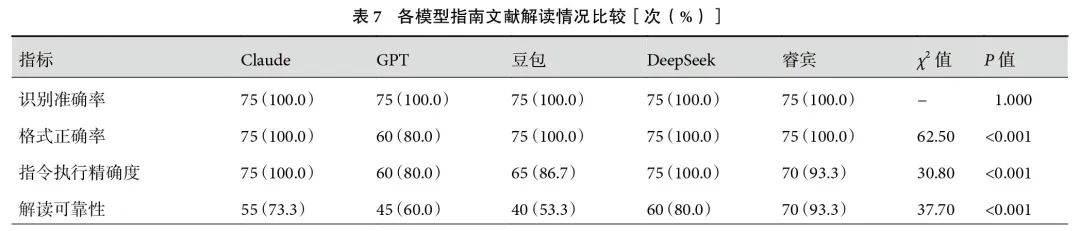
5个模型的RA间无显著差异。GPT的FA显著低于其他模型(80.0% vs. 100.0%,P<0.001)。Claude、DeepSeek和睿宾的IEA分别为100.0%、100.0%和93.3%,三者之间差异无统计学意义(P>0.05),其中Claude和DeepSeek的IEA高于GPT(100.0% vs. 80.0%,P=0.001)和豆包(100.0% vs. 86.7%,P=0.023)。CRR方面,睿宾和DeepSeek无显著差异(93.3% vs. 80.0%,P=0.123),且睿宾的CRR显著高于Claude(73.3%,P=0.015)、GPT(60%,P<0.001)和豆包(53.3%,P<0.001);见表7。在CCI方面,Claude和DeepSeek的CCI最高[0.71(0.53,0.91)vs. 0.80(0.65,0.91),P=0.343],其次是豆包和睿宾[0.58(0.32,0.78)vs. 0.45(0.38,0.55),P=0.094]。GPT的CCI为0.27(0.22,0.49),显著低于其他模型;见表2。
3 讨论
AI在临床医学领域展现出巨大潜力,广泛应用于影像分析、药物研发及风险预测等场景[24-26]。在科研辅助方面,当前研究主要集中在利用LLMs实现论文自动化摘要生成[27-28]。然而,对于AI辅助文献解读及LLMs长文本处理能力仍存在显著的研究空白。本研究首次系统评估了睿宾与主流LLMs在食管癌多类型医学文献解读任务中的性能差异。结果显示,睿宾在IEA和FA方面具有显著优势,印证了其通过与医学适配的提示工程及算法实现精准指令响应的设计优势。然而,睿宾在社论RA及总体CRR方面仍存在不足,凸显了医学专用模型进一步优化的关键路径。
值得注意的是,睿宾识别社论类型文献失败的原因可能与技术流程相关:在文献预处理阶段,光学字符识别将PDF格式转换为markdown格式时易遗漏页眉、页脚等图片元数据信息(如“Editorial”标识),导致模型无法准确识别。针对这一问题,目前研发团队已启动并完成两阶段优化:(1)在预处理环节增加文献结构校验模块,强化医学文献适配提示词工程;(2)引入用户交互机制:当模型对文献类型判断置信度低于阈值时,提供“重新生成解读内容”选项,允许用户手动触发二次解析。
睿宾的高IEA(97.3%)得益于其分层指令解构机制:首先通过语义解析识别核心指令(如“按照对应格式结构化解读文献”以及“排除冗余信息”等),再结合医学文献解读框架过滤非相关条目。这一策略显著降低了通用LLMs常见的指令偏移现象。值得注意的是,睿宾及通用LLMs在论著、综述和指南类型文献解读中展现出最优的指令执行力,可能源于这几类文献文本结构的高度标准化,便于算法提取关键指令锚点。未来可通过扩大指令训练集的文献类型覆盖度及数量(如社论等),进一步提升复杂指令的泛化能力。
在CCI方面,睿宾虽优于GPT,但较Claude仍存在显著差距。这种差异在指南类文献中尤为突出,其根本原因在于模型对结构化医学文献关键要素的覆盖不全,具体表现为对指南中核心内容(如“临床问题”和“推荐意见”等)的提取遗漏。系统提升医学专用模型的CCI需构建三阶段技术闭环:(1)预训练扩展:采用医学语义增强提示工程,明确各类文献核心要素边界[29];(2)微调优化:引入对抗学习,通过生成缺失要素的负样本促使模型识别信息提取盲区[30];(3)输出控制:集成完整性自评模块,要求模型输出内容覆盖度报告[31]。
睿宾的总体CRR仅84.0%,核心原因在于其初步解读功能(基于原文的提取和总结)与深度解读功能(基于原文的延伸分析与展望)边界和执行不够清晰。深度解读功能需要一定的创造性以提出合理的研究方向,但这种创造性必须严格建立在原文基础之上,以避免模型出现胡编乱造的情况。基于睿宾的情况,后续可采取以下措施控制幻觉:(1)针对性训练/微调:对于初步解读模型,强化编码器对输入文献的理解,优化解码器设计,以最大程度限制其生成源外信息;对深度解读模型,可采用诚实导向的强化学习方法,使模型学会在超出原文范围进行内容延伸时承认其不确定性[32–33]。(2)强化提示工程:针对初步和深度解读功能分别设计清晰和强约束的提示词,必要时采用过程监督方法回溯推理步骤,以暴露潜在的错误关联或跳跃性幻觉[34]。(3)输出核查与标记:对模型输出的所有非直接来源于原文的陈述进行自动化标记(如“推测”“展望”等),让用户参与输出信息可靠性决策[35]。
睿宾在医学文献格式化解读与精准指令执行方面优势显著。未来需重点提升社论文献识别能力,并通过增强训练数据、优化置信机制严格控制幻觉生成,以全面提升内容可靠性。
同时,需针对性优化模型对各类文献核心要素的覆盖能力,提升解读内容完整性。睿宾有望成为保障医学科研信息提取严谨性、提升科研效率的可靠辅助工具,推动AI辅助科研的实用化进程。
利益冲突:无。
作者贡献:温萍华负责数据分析及论文撰写;姜志杰、蒋欢负责数据收集、整理;袁湘蕾、胡兵负责内容指导与论文审校;周瑜、马虎和卢超负责模型搭建优化及研究结果解读。

